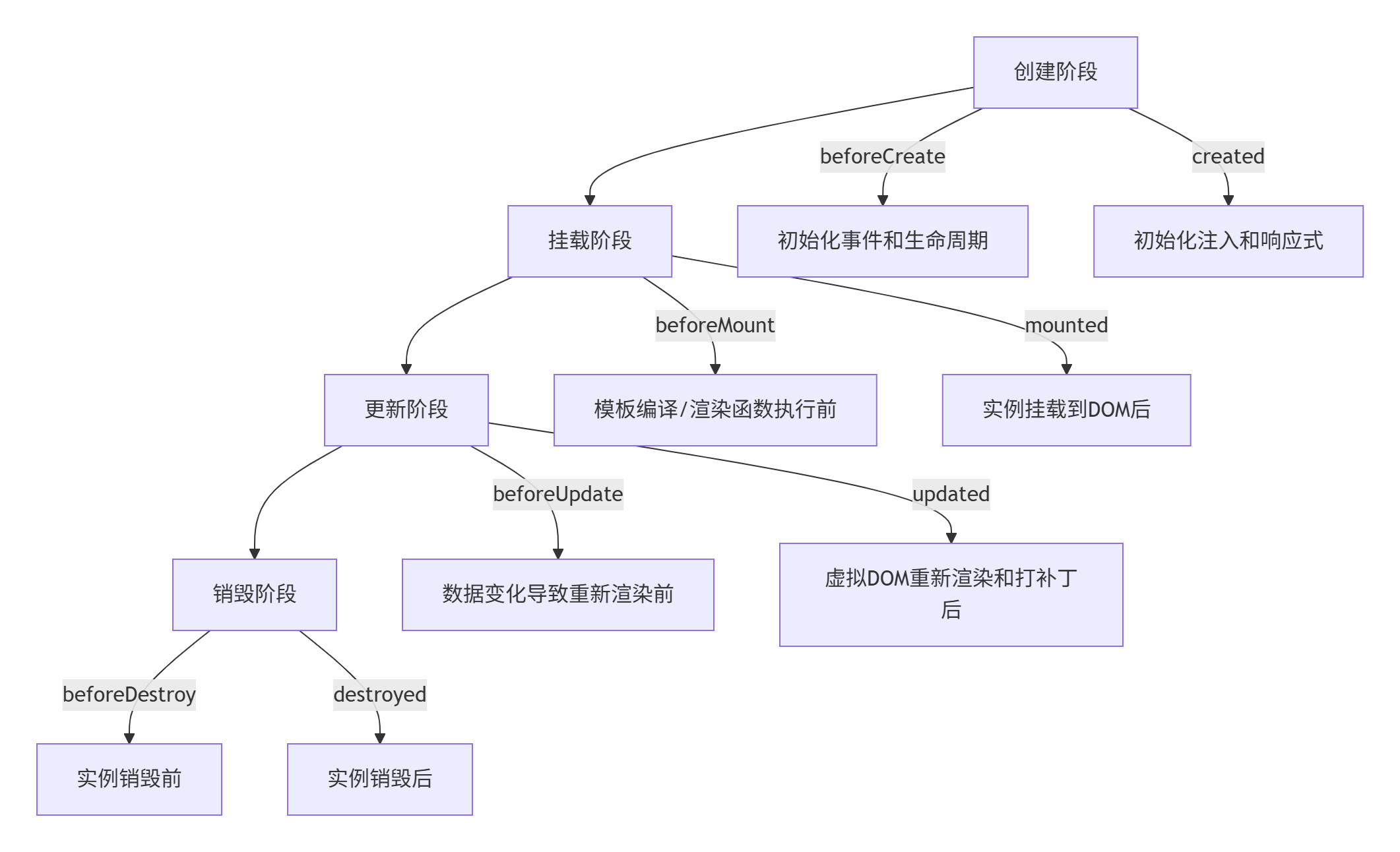
1.Vue2 生命周期
Vue2 的生命周期可以分为 4 个主要阶段,包含 8 个核心钩子函数
$el 是 Vue 实例的一个内置属性,表示 Vue 实例所管理的根 DOM 节点。它是 Vue 实例与真实 DOM 之间的桥梁。
生命周期阶段概览
- 分为 4 个阶段:
- 创建阶段:实例刚被创建,组件属性计算之前。
- 挂载阶段:
- 更新阶段:
- 销毁阶段:
一、创建阶段 (Initialization)
1. beforeCreate
- 触发时机:实例刚被创建,组件属性计算之前
- 特点:
- 无法访问 data、methods、computed 等选项
- 常用于开发中的初始化逻辑,如设置页面标题
window.document.title
beforeCreate() {
console.log('beforeCreate:', this.$data); // undefined
console.log('beforeCreate:', this.methodName); // undefined
}
2. created
- 触发时机:实例创建完成,属性已绑定
- 特点:
- 可以访问
data、methods、computed - 尚未挂载到 DOM,
$el不可用 - 常用于异步数据请求(不涉及dom)
- 可以访问
created() {
console.log('created:', this.$data); // 可访问
console.log('created:', this.methodName); // 可访问
console.log('created:', this.$el); // undefined
this.fetchData(); // 常见的数据请求时机
}
二. 挂载阶段 (DOM Mounting)
3. beforeMount
- 触发时机:模板编译完成,首次渲染前
- 特点:
$el已存在但内容尚未渲染- 服务端渲染时不调用
4. mounted
- 触发时机:实例被挂载到 DOM 后
- 特点:
- DOM 完全渲染完成
- 常用于操作 DOM 或初始化第三方库
- 注意:不保证所有子组件都已挂载
mounted() {
console.log('mounted:', this.$el); // 完全渲染的DOM
this.initChart(); // 初始化ECharts等库
}
三. 更新阶段 (Data Updates)
5. beforeUpdate
- 触发时机:数据变化导致重新渲染前
- 特点:
- 可以获取更新前的 DOM 状态
- 适合保存更新前的滚动位置等
beforeUpdate() {
this.scrollTop = this.$refs.list.scrollTop;
}
6. updated
- 触发时机:虚拟 DOM 重新渲染和打补丁后
- 特点:
- DOM 已更新完成
- 避免在此修改状态,可能导致无限循环
- 注意:不保证所有子组件都已重绘
updated() {
this.$refs.list.scrollTop = this.scrollTop;
}
四. 销毁阶段 (Destruction)
7. beforeDestroy
- 触发时机:实例销毁之前
- 特点:
- 实例仍然完全可用
- 必须在此清理定时器、事件监听等
beforeDestroy() {
clearInterval(this.timer);
window.removeEventListener('resize', this.handleResize);
}
8. destroyed
- 触发时机:实例销毁后
- 特点:
- 所有指令已解绑
- 所有子实例已销毁
- 常用于清理全局状态
destroyed() {
console.log('destroyed:', this.$el); // undefined
console.log('destroyed:', this.$data); // undefined
}
五. 特殊场景生命周期
keep-alive 组件特有钩子
activated() {
// 被 keep-alive 缓存的组件激活时调用
this.startPolling();
},
deactivated() {
// 被 keep-alive 缓存的组件停用时调用
this.stopPolling();
}
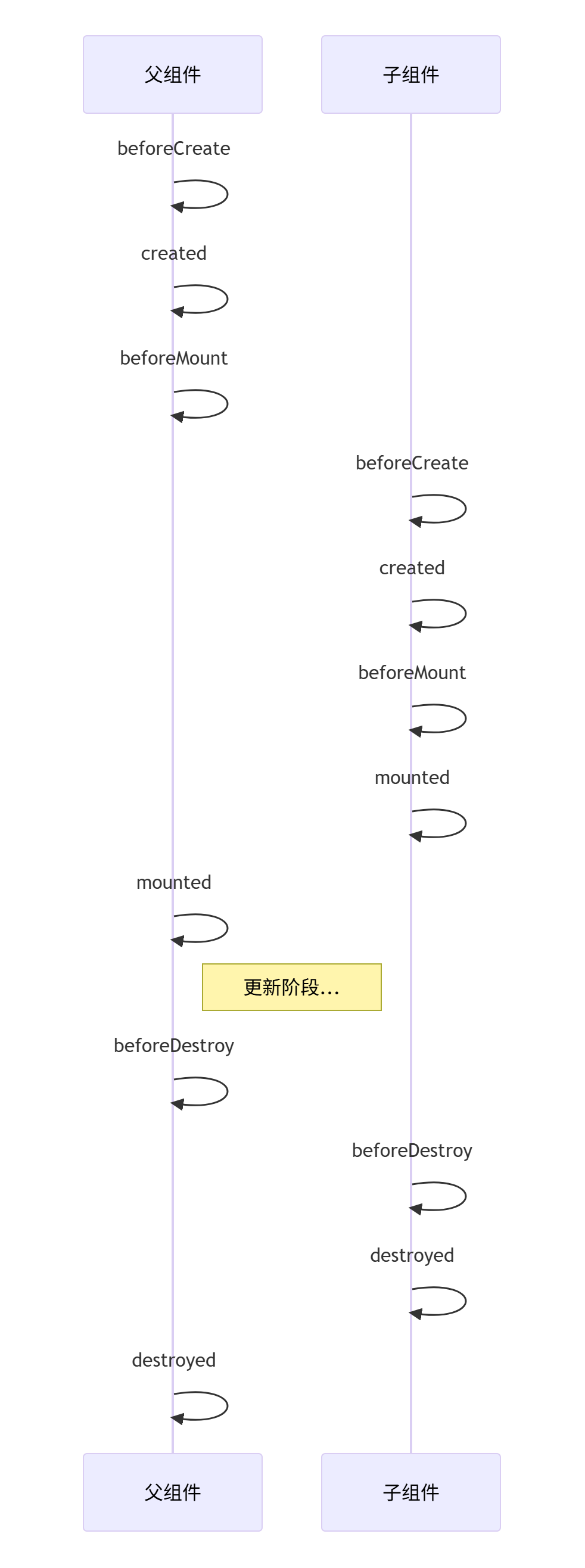
2.父子组件⽣命周期钩⼦执⾏顺序
特殊场景处理 keep-alive 组件中的销毁
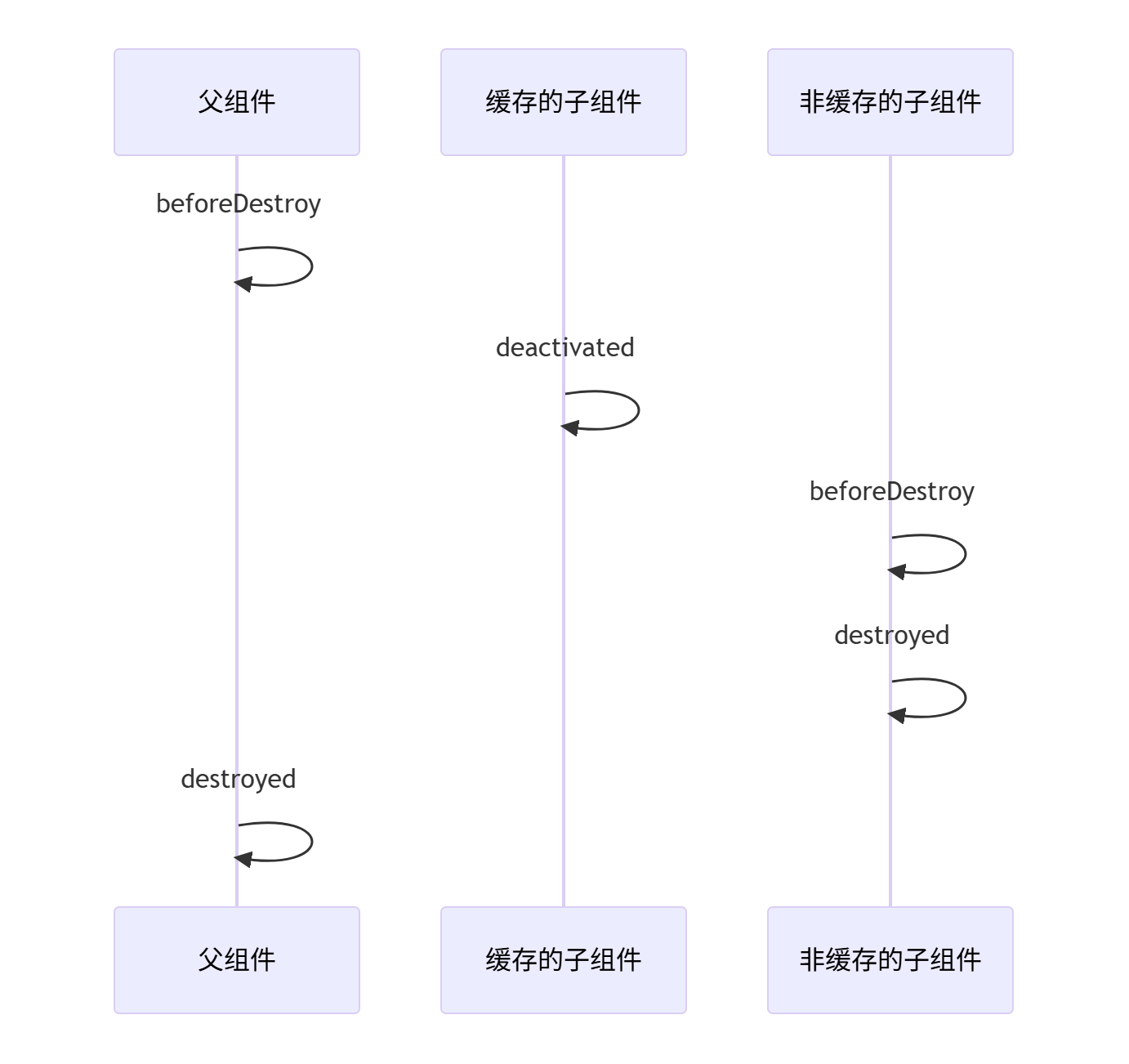
- 注意事项
- 子组件总是在父组件destroyed之前完成销毁
- 销毁顺序由Vue内部管理,开发者无法改变
3.v-model是如何实现双向绑定的(⭐️)
vue2.0
v-model是⽤来在表单控件或者组件上创建双向绑定的,他的本质是 v-bind 和 v-on 的语法糖,在 ⼀个组件上使⽤ v-model ,默认会为组件绑定名为 value 的 prop 和名为 input 的事件。
v-model并不是真正的"双向数据流",而是单向数据流 + 自动事件监听的语法糖。
<!-- 使用v-model -->
<input v-model="message">
<!-- 等价于 -->
<input
:value="message"
@input="message = $event.target.value">
- Vue 模板编译器会将
v-model转换为对应的属性和事件:
// 编译前
const ast = parse(`<input v-model="message">`)
// 编译后
const code = generate(ast, {
directives: {
model: (dir, node) => {
// 根据不同元素类型生成不同代码
if (node.tag === 'input') {
return `{
value: (${dir.value}),
onInput: $event => { ${dir.value} = $event.target.value }
}`
}
// 其他元素处理...
}
}
})
Vue3.0
- Vue3 对
v-model进行了重大改进,使其更加灵活和强大
| 特性 | Vue2 | Vue3 |
|---|---|---|
| 默认prop/event | value/input | modelValue/update:modelValue |
| 多v-model支持 | 不支持(其实是支持,一般不推荐) | 支持多个v-model绑定 |
| 修饰符处理 | 有限支持(.trim等) | 可自定义修饰符处理逻辑 |
- Vue3 的编译器会将 v-model 转换为标准的
props和emits:
// 编译前
<MyComponent v-model="title" />
// 编译后
h(MyComponent, {
modelValue: title,
'onUpdate:modelValue': value => (title = value)
})
- Vue3 的 props 是只读的,必须通过 emit 更新:
// 错误!Vue3中直接修改props会警告
props.modelValue = newValue
// 正确方式
emit('update:modelValue', newValue)
4.Vue 非父子通信方式(⭐️)
1、EventBus (实例化一个空Vue作为事件中心管理)
// bus.js
import Vue from 'vue'
export default new Vue()
import Bus from 'bus'
// 监听事件
Bus.$on('updateData', value => { })
// 触发事件
Bus.$emit('updateData', 5)
// 注销事件
Bus.$off('updateData')
2、$attrs/$listeners(跨级通信)
Vue2.4 提供适用于多层嵌套组件通信的方法
$attrs:包含了父作用域中不被 prop 所识别 (且获取) 的特性绑定 (class 和 style 除外)。当一个组件没有声明任何 prop 时,这里会包含所有父作用域的绑定 (class 和 style 除外),并且可以通过 v-bind="$attrs" 传入内部组件。通常配合 interitAttrs 选项一起使用。
$listeners:包含了父作用域中的 (不含 .native 修饰器的) v-on 事件监听器。它可以通过 v-on="$listeners" 传入内部组件
<!-- 中间组件 -->
<child-component v-bind="$attrs" v-on="$listeners"></child-component>
<!-- 祖先组件 -->
<middle-component :message="msg" @custom-event="handleEvent">
3、Observable
Vue.observable 是 Vue2.6 新增的全局 API,用于创建响应式对象,可以替代部分 Vuex 的小型状态管理需求。
与 Vuex 的区别
| 特性 | Vue.observable | Vuex |
|---|---|---|
| 复杂度 | 轻量级 | 功能完整 |
| 适用场景 | 简单状态共享 | 中大型应用 |
| 调试工具 | 不支持 | 支持DevTools |
| 响应式原理 | 与组件data相同 | 专门的状态管理机制 |
// 创建 store
import Vue from 'vue'
// 通过Vue.observable创建一个可响应的对象
export const store = Vue.observable({
userInfo: {},
roleIds: []
})
// 定义 mutations, 修改属性
export const mutations = {
setUserInfo(userInfo) {
store.userInfo = userInfo
},
setRoleIds(roleIds) {
store.roleIds = roleIds
}
}
// 在组件中引用
<template>
<div>
{{ userInfo.name }}
</div>
</template>
<script>
import { store, mutations } from '../store'
export default {
computed: {
userInfo() {
return store.userInfo
}
},
created() {
mutations.setUserInfo({
name: '子君'
})
}
}
</script>
4、provide/inject
// 祖先组件
export default {
provide() {
return {
sharedData: this.sharedState
}
},
data() {
return {
sharedState: {
message: 'Hello'
}
}
}
}
// 后代组件
export default {
inject: ['sharedData'],
created() {
console.log(this.sharedData.message) // 'Hello'
}
}
- 缺点
- 单向数据流:祖先组件不知道哪些后代组件使用它
- 响应式问题:直接提供基本类型值不是响应式的
5、原型全局挂载
// main.js
import Vue from 'vue'
import App from './App.vue'
Vue.prototype.$globalData = {
sharedValue: 'Global data'
}
new Vue({
render: h => h(App)
}).$mount('#app')
// 任意组件中访问
this.$globalData.sharedValue
6、Vuex
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。
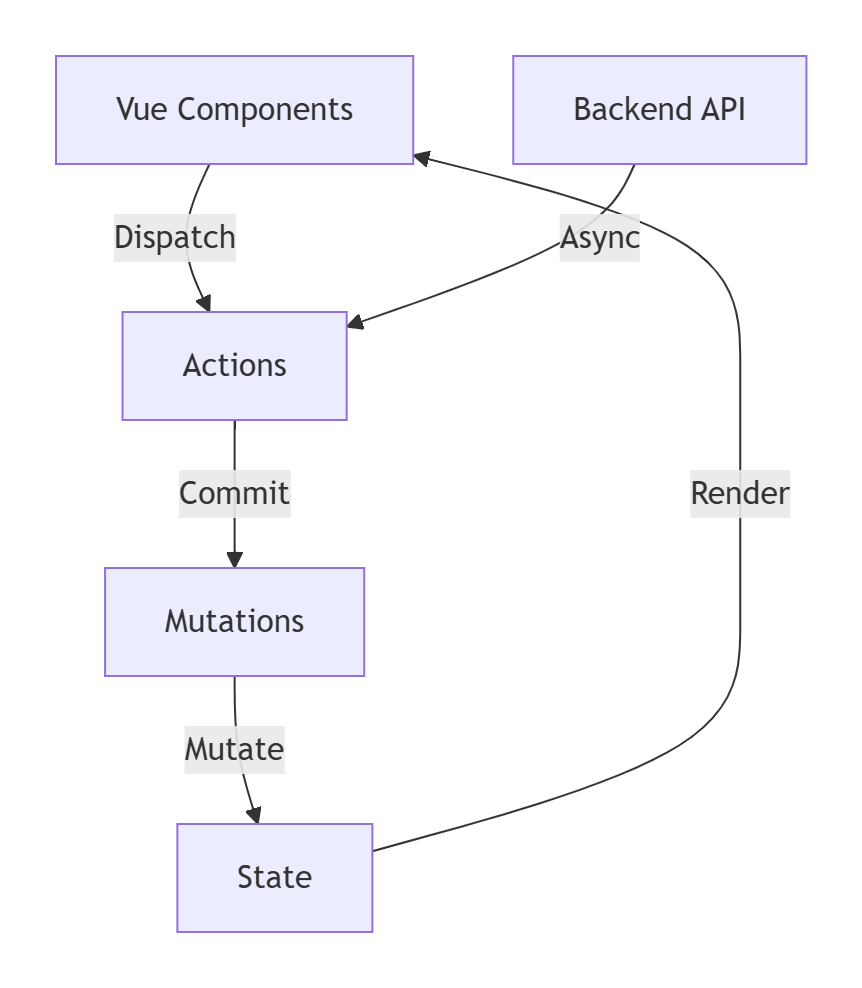
- 数据流规则
- 单向数据流:
View→Actions→Mutations→State→View - 同步修改:只有
mutations能直接修改state - 异步操作:在
actions中处理异步逻辑
- 单向数据流:
简单来说,这个 store 就是用来存储数据
存储数据方式有很多种,比如变量、数组、cookie、localstorage、session 等等
但是由于 store 是内存机制,而不是缓存机制,当前页面一旦刷新或者通过路由跳转亦或是关闭,都会导致 store 初始化
因此在之前就暂时把 store 看成一个多功能的全局变量
而 Vuex 和单纯的全局对象又有点不同
1、Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
2、不能直接改变 store 中的状态。改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样可以方便地跟踪每一个状态的变化。
State:(单一状态树)
1、State 就是数据源存放地
2、State 里面存放的数据是响应式的,Vue 组件从 store 中读取数据,若是 store 中的数据发生改变,依赖这个数据的组件也会发生更新
// 定义
const state = {
user: {
id: null,
name: ''
}
}
// 组件访问
computed: {
// 方式1:直接访问
username() {
return this.$store.state.user.name
},
// 方式2:mapState辅助函数
...mapState({
theme: state => state.settings.theme
})
}
Getter:(派生状态)
1、getters 可以对 State 进行计算操作,它就是 Store 的计算属性
2、虽然在组件内也可以做计算属性,但是 getters 可以在多组件之间复用
3、如果一个状态只在一个组件内使用,是可以不用 getters
// 定义
const getters = {
// 带参数的计算属性
getUserById: (state) => (id) => {
return state.users.find(user => user.id === id)
},
// 组合多个getter
userProfile: (state, getters) => {
return {
...state.user,
preferences: getters.userPreferences
}
}
}
// 组件使用
computed: {
...mapGetters(['currentUser']),
// 带参数的getter
user() {
return this.$store.getters.getUserById(this.userId)
}
}
Mutation:(同步事务)
更改 Vuex 的 store 中的状态的唯一方法是提交 mutation。
// mutation-types.js
export const SET_USER = 'SET_USER'
// store.js
mutations: {
[SET_USER](state, payload) {
state.user = payload
}
}
// 组件调用
this.$store.commit(SET_USER, userData)
Action 类似于 mutation,不同在于:
Action 提交的是 mutation,而不是直接变更状态。 Action 可以包含任意异步操作。
Moudle
每个 state 对应一个 moudle
5.Vue-router
Vue是单页应用(SPA),只有一个html文件,而vue-router就是vue进行页面替换和更新的组件。
由route, routes, router组成。
1、路由之间跳转:
- 声明式(标签跳转)
- 编程式(js 跳转)
2、路由模式以及原理:
更新视图但不重新请求页面,是前端路由原理的核心之一,目前在浏览器环境中这一功能的实现主要有 3 种方式
| 模式 | 原理 | 特点 | 使用场景 |
|---|---|---|---|
| hash模式 | 使用 URL hash (#) | 兼容性好,无需服务器配置 | 传统Web应用 |
| history模式 | 利用 HTML5 History API | URL更简洁,需要服务端支持 | 现代Web应用,SEO友好 |
| abstract模式 | 基于内存的路由 | 无URL变化,适合非浏览器环境 | 移动端原生应用,测试环境 |
const router = new VueRouter({
mode: 'history', // 可选: 'hash' | 'history' | 'abstract'
routes: [...]
})
● hash: 使用 URL hash 值来作路由。默认模式。
● history: 依赖 HTML5 History API 和服务器配置。查看 HTML5 History 模式。
● abstract: 支持所有 JavaScript 运行环境,如 Node.js 服务器端
Hash模式
hash模式的工作原理是 hashchange 事件,可以在window监听hash的变化。我们在url后面随便添加一个#xx触发这个事件。
window.onhashchange = function(event){
console.log(event)
}
hash即浏览器url中#后面的内容,包含#。hash是URL中的锚点,代表的是网页中的一个位置,单单改变#后的部分,浏览器只会加载相应位置的内容,不会重新加载页面。
- 即#是用来指导浏览器动作的,对服务器端完全无用,HTTP请求中,不包含#。
- 每一次改变#后的部分,都会在浏览器的访问历史中增加一个记录,使用”后退”按钮,就可以回到上一个位置。
- 所以说Hash模式通过锚点值的改变,根据不同的值,渲染指定DOM位置的不同数据。
History模式
HTML5 History API提供了一种功能,能让开发人员在不刷新整个页面的情况下修改站点的URL,就是利用 history.pushState和history.replaceState API 来完成 URL 跳转而无须重新加载页面;
由于hash模式会在url中自带#,如果不想要很丑的 hash,我们可以用路由的 history 模式,只需要在配置路由规则时,加入"mode: 'history'",这种模式充分利用 history.pushState API 来完成 URL 跳转而无须重新加载页面。
有时,history模式下也会出问题:
- hash模式下:xxx.com/#/id=5 请求地址为 xxx.com,没有问题。
- history模式下:xxx.com/id=5 请求地址为 xxx.com/id=5,如果后端没有对应的路由处理,就会返回404错误;
为了应对这种情况,需要后台配置支持:
在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app 依赖的页面。
3、vue router传参的三种方式
- 1、params传参
this.$router.push({ name: 'news', params: { type: 1 }})
此时浏览器url上是看不到任何参数的,像这样http://localhost:9530/news
对于像path: '/detail/:id'这样的携带参数的动态路由,传参时也应当使用params,动态路由传参是可以再url上看到的,像这样http://localhost:9530/detail/121
- 2、query传参
this.$router.push({ path: 'news', query: { type: 1 }})
此时浏览器url上是可以看得到参数的,像这样http://localhost:9530/news/?type=1 通过query传的参数在页面刷新时不会丢失。
- 3、props传参
{
name: 'news',
path: '/news',
component: () => import('@/views/news'),
meta: { title: '新闻详情' },
props: { type: 1 }
}
通过props的方式传参时,在组件内的取值方式也是通过props,像父子组件传值那样
4、动态路由
Vue 动态路由,就是基于 router.addRoutes | router.addRoute 这个 api 的一个功能实现
// 动态路由匹配
const routes = [
// 动态参数以冒号开头
{ path: '/user/:id', component: User },
// 可选参数
{ path: '/user/:id?', component: User },
// 多段动态参数
{ path: '/user/:id/post/:postId', component: Post }
]
// 高级匹配规则
{
path: '/user/:id(\\d+)', // 只匹配数字ID
path: '/files/:path*', // 匹配零个或多个路径段
path: '/docs/:chapter?' // 可选参数
}
5、vue-router 路由守卫
第一种:全局前置守卫 (beforeEach)
第二种:路由独享守卫 (beforeEnter)
第三种:组件内守卫
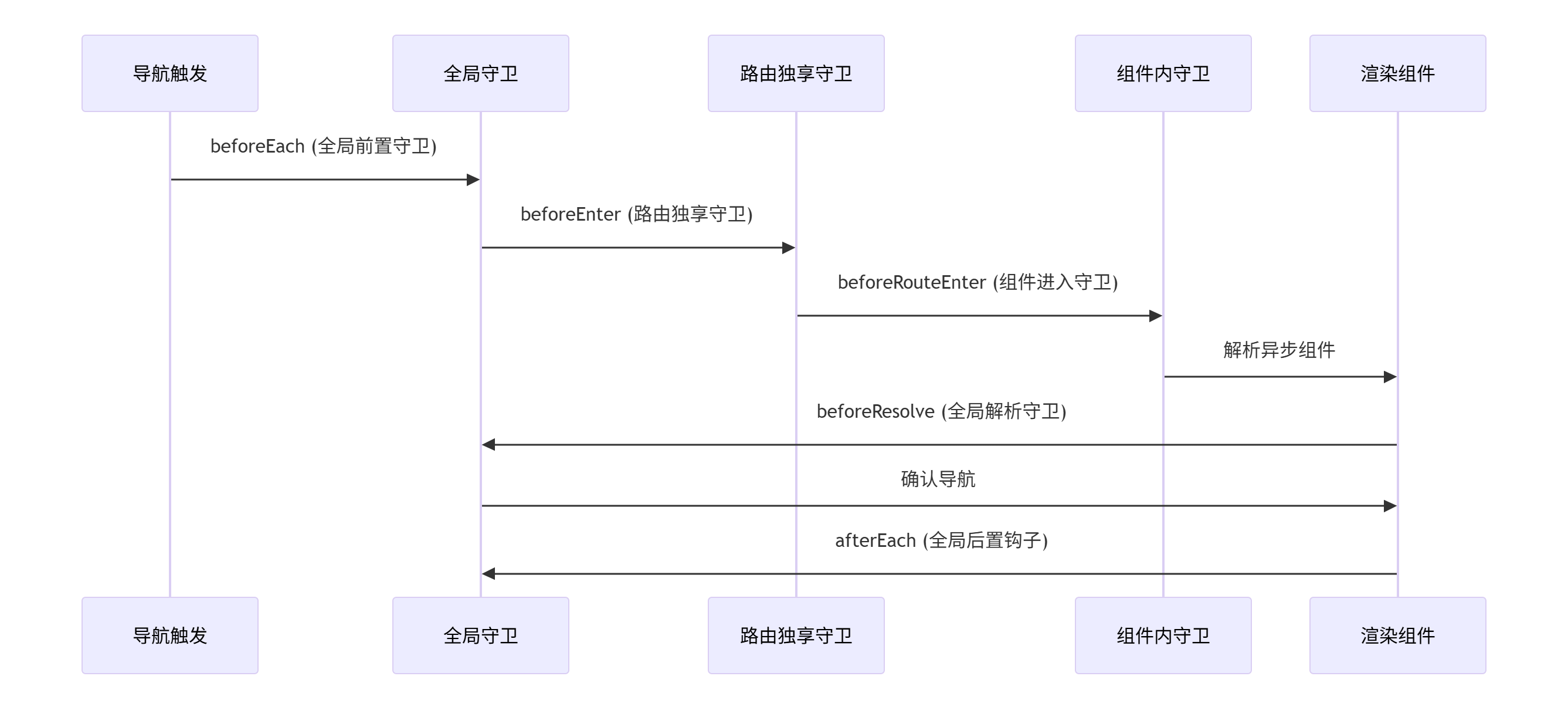
1. 全局前置守卫
典型应用:权限控制
- 业务场景:
- 登录状态验证
- 权限路由过滤
- 维护模式拦截
- 多租户路由处理
router.beforeEach((to, from, next) => {
// 1. 免登录白名单
const whiteList = ['/login', '/register']
if (whiteList.includes(to.path)) return next()
// 2. 检查登录状态
const isAuthenticated = checkAuth()
// 3. 需要登录但未登录
if (to.meta.requiresAuth && !isAuthenticated) {
return next({
path: '/login',
query: { redirect: to.fullPath } // 记录目标路由
})
}
// 4. 已登录但访问登录页
if (to.path === '/login' && isAuthenticated) {
return next('/dashboard')
}
next()
})
2. 路由独享守卫 (beforeEnter)
典型应用:路由级权限
const routes = [
{
path: '/admin',
component: AdminPanel,
beforeEnter: (to, from, next) => {
// 检查管理员权限
if (!store.getters.isAdmin) {
next('/403') // 无权限跳转
} else {
next()
}
},
meta: { requiresAuth: true }
}
]
- 业务场景:
- 特定路由的权限控制
- 路由参数验证
- 动态路由预检查
3. 组件内守卫
(1) beforeRouteEnter - 进入组件前
export default {
beforeRouteEnter(to, from, next) {
// 无法访问this,但可通过回调访问
next(vm => {
// 通过vm访问组件实例
vm.fetchData(to.params.id)
})
}
}
(2) beforeRouteLeave - 离开组件前
export default {
data() {
return {
formChanged: false
}
},
beforeRouteLeave(to, from, next) {
if (this.formChanged) {
if (confirm('有未保存的更改,确定离开?')) {
next()
} else {
next(false) // 取消导航
}
} else {
next()
}
}
}
- 业务场景:
- 表单未保存提示
- 数据预加载
- 滚动位置保存
- 组件特定权限检查
6、$route 和$router 的区别
$router为 VueRouter 的实例,相当于一个全局的路由对象,里面含有很多属性和子对象,例如 history 对象$route相当于当前路由对象,属于局部对象,以从里面获取 name,path,params,query 等
| 特性 | $route | $router |
|---|---|---|
| 类型 | 当前路由信息对象(只读) | 路由实例(可操作路由的方法集合) |
| 数据性质 | 反映当前路由状态(响应式) | 提供路由操作方法 |
| 主要用途 | 获取路由参数、查询参数等 | 编程式导航、路由控制 |
| 修改方式 | 不可直接修改 | 通过方法修改路由 |
| 访问方式 | this.$route | this.$router |
7、Vue路由懒加载3种方式
- Vue异步组件
component:resolve => require(['@/components/Foo'],resolve)
- ES6的import()
const Foo = () => import('../components/Foo')
- webpack的require.ensure()
component:r=>
require.ensure([],()=>r(require('@/components/home')),'funcDemo')
常见问题及解决方案
1. 动态路由权限控制
// 初始化基础路由
const constRoutes = [
{ path: '/login', component: Login },
{ path: '/404', component: NotFound }
]
// 动态添加路由
function addRoutes() {
const accessRoutes = generateRoutes(userRole)
router.addRoutes(accessRoutes)
router.addRoutes([{ path: '*', redirect: '/404' }])
}
2. 页面切换动画
<transition name="fade" mode="out-in">
<router-view></router-view>
</transition>
<style>
.fade-enter-active, .fade-leave-active {
transition: opacity 0.3s;
}
.fade-enter, .fade-leave-to {
opacity: 0;
}
</style>
6.diff算法和虚拟dom
6-1、虚拟 DOM
要理解 Diff 算法,就得先理解好虚拟 DOM。
虚拟 DOM(Virtual DOM)是一种内存中的轻量级数据表示,它是对真实 DOM 的抽象描述。
// 真实 DOM 和 虚拟 DOM 是可以相互转化
<div id="container" class="p-container">
<h1>Real DOM</h1>
</div>
const VirtualDOM = {
tag: 'div',
data: {
id: 'container',
class: 'p-container'
},
children: [
{
tag: 'h1',
data: {},
children: ['Real DOM'],
},
]
}
虚拟 DOM 工作流程
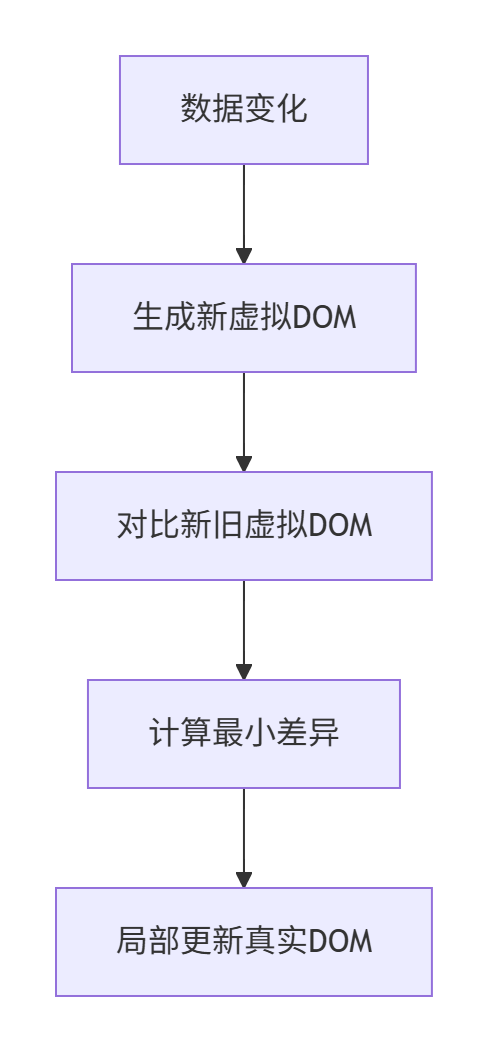
6-2、为什么要有虚拟DOM
- 虚拟 DOM 的优势
- 性能优化:减少直接操作真实 DOM 的昂贵开销
- 跨平台能力:可以在非浏览器环境渲染(如 SSR、Weex)
- 声明式编程:开发者只需关心数据,不用手动操作 DOM
1、跨平台渲染。借助虚拟 DOM 后 FrontEnd 可以进行移动端、小程序等开发。因为虚拟 DOM 本身只是一个 JavaScript 对象,所以可以先由 FE 们写 UI 并抽象成一个虚拟 DOM,再由安卓、IOS、小程序等原生实现根据虚拟 DOM 去渲染页面(React Native、Weex)。
2、函数式的 UI 编程。将 UI 抽象成对象的形式,相当于可以以编写 JavaScript 的形式来写 UI。
3、网上 Blog 常常会说到虚拟 DOM 会有更好的性说能,因为虚拟 DOM 只会在 Diff 后修改一次真实 DOM,所以不会有大量的重排重绘消耗。并且只更新有变动的部分节点,而非更新整个视图。但我对这句话是存疑的,通过下文的 Diff 算法源码可以发现,Vue2 它的 Diff 是每次比对到匹配到的节点后就去修改真实 DOM 的,并不是等所有 Diff 完后再修改一次真实 DOM 而已。
6-3、什么是 Diff 算法
Diff算法,全称为Difference算法,通过比较两个对象(如两个文本文件、两个虚拟DOM树等)来找出它们之间的差异,并根据这些差异生成一个补丁文件或差异描述,以便能够将这些差异应用到另一个对象上。
6-4、Vue2 中 Diff 原理
当对新旧两个虚拟 DOM 做 Diff 时,Vue 采用的思想是同级比较、深度优先、双端遍历。
5-4-1、同级比较:
同级比较指的是只比对两个相同层级的 VNode,如果两者不一样了,就不再去 Diff 它们的子节点,更不会去跨层级比较,而是直接更新它。
这是因为在我们平时的操作,很少出现将一个 DOM 节点进行跨层级移动,比如将原来的父节点移动到它子节点的位置上。
所以 Diff 算法就没有为这个极少数的情况专门去跨层级 Diff,毕竟为此得不偿失,这也是 Diff 算法时间复杂度能从 O(n^3) 优化到 O(n) 的原因之一。
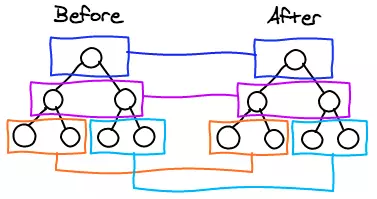
6-4-2、深度优先
先比较完一个子节点后,就去比较这个子节点的子孙节点,都递归完后再来遍历它的兄弟节点。
如下图的一个 DOM 结构,节点的编号就是它们的遍历顺序。
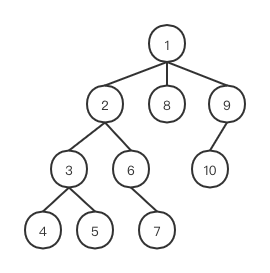
那么为什么要使用深度优先遍历,广度优先遍历不行么?
深度优先遍历使用到的是栈结构,进行深度递归的时候,栈中保存的是当前节点的父元素和祖先元素,栈中存储的最大节点个数就是 DOM 树最大的层级数。
而广度优先遍历使用的是队列结构,进行广度递归的时候,队列中保存的是下一层的节点,队列中存储的最大节点个数就是 DOM 树最大的层级节点数。
而在通常情况下,一个 DOM 树的层级数是会少于它的层级节点数的(比如一个列表信息组件),所以使用深度优先遍历占用的空间和消耗会更小些。
6-4-3、双端比较
双端比较指的是在 Diff 新旧子节点时,使用了四个指针分为四种比较方法
oldStartIdx 表示旧 VNode 从左边开始 Diff 的节点,初始值为第一个子节点
oldEndIdx 表示旧 VNode 从右边开始 Diff 的节点,初始值为最后一个子节点
newStartIdx 表示新 VNode 从左边开始 Diff 的节点,初始值为第一个子节点
newEndIdx 表示新 VNode 从右边开始 Diff 的节点,初始值为最后一个子节点
6-5、Vue的key
6-5-1、为什么要加上key
Vue官网的解释:
key 的特殊 attribute 主要用在 Vue 的虚拟 DOM 算法,在新旧 nodes 对比时辨识 VNodes。
如果不使用 key,Vue 会使用一种最大限度减少动态元素并且尽可能的尝试就地修改/复用相同类型元素的算法。
而使用 key 时,它会基于 key 的变化重新排列元素顺序,并且会移除 key 不存在的元素。
6-5-2、为什么要求key唯一
Vue的源码中有一个sameVnode的方法,这个方法放回布尔值,用来判断两个节点是否相同。
function sameVnode (a, b) {
return (
a.key === b.key && (
(
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
) || (
isTrue(a.isAsyncPlaceholder) &&
a.asyncFactory === b.asyncFactory &&
isUndef(b.asyncFactory.error)
)
)
)
}
6-5-3、为什么不建议用数组的index作为key
<ul>
<li key="0">a</li>
<li key="1">b</li>
<li key="2">c</li>
</ul>
举个例子,上面是初始数据,然后在数据前插入一个新数据,变成如下的列表
<ul>
<li key="0">xxx</li>
<li key="0">a</li>
<li key="1">b</li>
<li key="3">c</li>
</ul>
按理说,最理想的结果是:只插入一个li标签新节点,其他都不动,确保操作DOM效率最高。
通过Vue的源码可以看到只有在非production的情况下才会显示key重复的warn提示
if (process.env.NODE_ENV !== 'production') {
checkDuplicateKeys(ch);
}
7.Vue 数据双向绑定
数据双向绑定
在 vue 上使用 v-model 指令执行数据的双向绑定
实现数据绑定的做法有大致如下几种
- 发布者-订阅者模式(backbone.js)
- 脏值检查(angular.js)
- 数据劫持(vue.js)
vue.js 则是采用数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty()来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
要实现 mvvm 的双向绑定,就必须要实现以下几点
1、实现一个数据监听器 Observer,能够对数据对象的所有属性进行监听,如有变动可拿到最新值并通知订阅者
2、实现一个指令解析器 Compile,对每个元素节点的指令进行扫描和解析,根据指令模板替换数据,以及绑定相应的更新函数
3、实现一个 Watcher,作为连接 Observer 和 Compile 的桥梁,能够订阅并收到每个属性变动的通知,执行指令绑定的相应回调函数,从而更新视图
4、mvvm 入口函数,整合以上三者
上述流程如图所示:
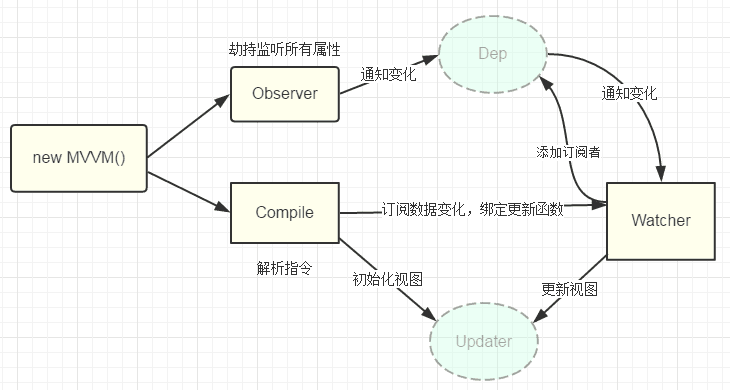
实现 Compile
compile 主要做的事情是解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图,如图所示:
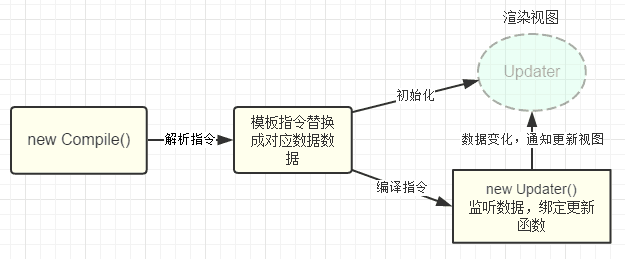
因为遍历解析的过程有多次操作 dom 节点,为提高性能和效率,会先将跟节点 el 转换成文档碎片 fragment 进行解析编译操作,解析完成,再将 fragment 添加回原来的真实 dom 节点中
实现 Watcher
Watcher 订阅者作为 Observer 和 Compile 之间通信的桥梁,主要做的事情是:
1、在自身实例化时往属性订阅器(dep)里面添加自己
2、自身必须有一个 update()方法
3、待属性变动 dep.notice()通知时,能调用自身的 update()方法,并触发 Compile 中绑定的回调,则功成身退。
实现 MVVM
MVVM 作为数据绑定的入口,整合 Observer、Compile 和 Watcher 三者,通过 Observer 来监听自己的 model 数据变化,通过 Compile 来解析编译模板指令,最终利用 Watcher 搭起 Observer 和 Compile 之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据 model 变更的双向绑定效果。
8.Vue 中的 computed 是如何实现(⭐️)
一、基本实现机制
Vue的computed本质是一个响应式的计算属性,其核心原理基于依赖收集和缓存机制。当访问computed时,会执行getter函数并收集依赖的响应式数据;当依赖数据变化时,会标记computed为"脏"状态,下次访问时重新计算并缓存结果
二、核心实现步骤
1. 初始化阶段
当组件初始化时,Vue 会处理 computed 属性:
function initComputed(vm, computed) {
const watchers = vm._computedWatchers = Object.create(null);
for (const key in computed) {
const getter = typeof computed[key] === 'function'
? computed[key]
: computed[key].get;
// 为每个计算属性创建计算watcher
watchers[key] = new Watcher(
vm,
getter,
noop, // 无回调
{ lazy: true } // 标记为计算属性watcher
);
// 在组件实例上定义计算属性
defineComputed(vm, key, userDef);
}
}
2. 依赖收集过程
当计算属性首次被访问时:
- 触发 getter 函数:
function createComputedGetter(key) {
return function computedGetter() {
const watcher = this._computedWatchers[key];
if (watcher.dirty) {
watcher.evaluate(); // 重新计算值
}
if (Dep.target) {
watcher.depend(); // 收集依赖
}
return watcher.value;
}
}
执行计算函数:计算过程中访问的响应式数据会将此计算 watcher 收集为自己的依赖
依赖关系建立:
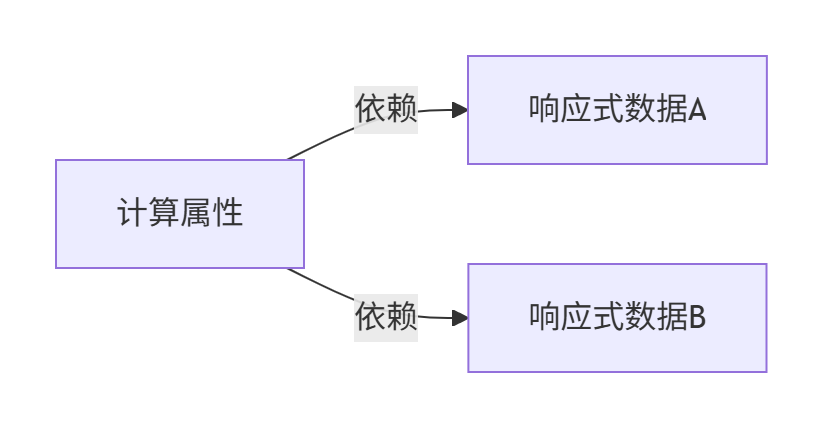
3. 缓存与更新机制
缓存机制:
- 计算属性会缓存上一次计算的结果
- 只有依赖项变化时才会重新计算
更新触发条件:
// 当依赖项发生变化时
notify() {
this.subs.forEach(watcher => {
if (watcher.lazy) {
watcher.dirty = true; // 标记为脏数据
} else {
watcher.update();
}
});
}
9.style标签加scoped的作用以及原理
一、基本作用
<style scoped> 的作用是实现组件级别的样式隔离封装,确保样式只作用于当前组件,不会影响其他组件。
<template>
<div class="example">Hello</div>
</template>
<style scoped>
.example {
color: red;
}
</style>
二、核心原理
Vue 通过 PostCSS 插件和 HTML 转换实现样式作用域隔离:
1. HTML 处理
为当前组件内的所有 DOM 元素添加一个唯一的数据属性
每个组件会获得一个唯一的哈希标识(如 data-v-f3f3eg9), 哈希标识基于组件文件路径和内容计算得出
<!-- 转换前 -->
<div class="example"></div>
<!-- 转换后 -->
<div class="example" data-v-f3f3eg9></div>
2. CSS 处理
将样式选择器转换为属性选择器形式
/* 转换前 */
.example { color: red; }
/* 转换后 */
.example[data-v-f3f3eg9] { color: red; }
三、样式作用域规则
- 仅影响当前组件模板中的元素
- 不影响子组件的根元素(子组件根元素会同时拥有父组件和子组件的
scoped属性) - 不影响通过
v-html动态插入的内容
四、深度选择器
当需要影响子组件样式时,可以使用 ::v-deep、>>> 或 /deep/(后两者已废弃)
/* 深度作用选择器 */
::v-deep(.child-component) {
color: blue;
}
/* 转换后 */
[data-v-f3f3eg9] .child-component {
color: blue;
}
10.vue template渲染原理(⭐️)
Vue 的模板渲染过程是将模板(template)转换为真实 DOM 的过程
一、整体渲染流程
模板(template) → 解析(AST) → 优化 → 生成渲染函数 → 虚拟DOM → 真实DOM
二、核心处理阶段
1. 模板解析阶段
将模板字符串转换为AST(抽象语法树):
// 示例模板
<div id="app">
<p>{{ message }}</p>
</div>
// 转换为AST后
{
type: 1,
tag: 'div',
attrsList: [{name: 'id', value: 'app'}],
children: [{
type: 1,
tag: 'p',
children: [{
type: 2,
expression: '_s(message)',
text: '{{ message }}'
}]
}]
}
- 解析器工作流程:
- 使用正则表达式匹配标签、属性、文本等
- 通过栈结构维护DOM层级关系
- 生成带有节点类型、属性、子节点等信息的AST树
2. 优化阶段
标记静态节点:
// 静态节点示例
<p>静态内容</p>
// 优化后AST节点
{
static: true,
staticRoot: true,
// ...其他属性
}
- 优化器会:
- 标记所有静态节点(不依赖响应式数据的节点)
- 标记静态根节点(子节点全是静态的父节点)
- 在后续更新中跳过这些静态节点的比对
3. 代码生成阶段
将AST转换为渲染函数代码:
// 生成结果示例
with(this) {
return _c('div', {attrs: {"id": "app"}}, [
_c('p', [_v(_s(message))])
])
}
- 生成的渲染函数包含Vue内部方法:
- _c: 创建虚拟节点
- _v: 创建文本虚拟节点
- _s: 转换为字符串
三、虚拟DOM与patch过程
1. 首次渲染
// 执行渲染函数生成虚拟DOM
const vnode = vm._render()
// 将虚拟DOM转为真实DOM
vm._update(vnode)
2. 更新过程
- 数据变化触发setter
- 通知依赖(Watcher)更新
- 重新执行渲染函数生成新虚拟DOM
- 新旧虚拟DOM对比(patch)
- 计算最小差异并更新真实DOM
3. Diff算法核心
- 同级比较策略:
- 只比较同层级节点,不跨级比较
- 通过key标识相同节点
- 采用双端比较算法优化性能
// 简单的diff示例
function updateChildren(parentElm, oldCh, newCh) {
let oldStartIdx = 0, newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let newEndIdx = newCh.length - 1
// ...
}
11. new Vue 发生了什么
new 关键字在 Javascript 语言中代表实例化是一个对象,而 Vue 实际上是一个类
可以看到 Vue 只能通过 new 关键字初始化,然后会调用 this._init 方法
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)
) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}
Vue 初始化主要就干了几件事情
合并配置,初始化生命周期,初始化事件中心,初始化渲染,初始化 data、props、computed、watcher 等等
Vue.prototype._init = function (options?: Object) {
const vm: Component = this
// a uid
vm._uid = uid++
let startTag, endTag
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
startTag = `vue-perf-start:${vm._uid}`
endTag = `vue-perf-end:${vm._uid}`
mark(startTag)
}
// a flag to avoid this being observed
vm._isVue = true
// merge options
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
initInternalComponent(vm, options)
} else {
vm.$options = mergeOptions(
resolveConstructorOptions(vm.constructor),
options || {},
vm
)
}
/* istanbul ignore else */
if (process.env.NODE_ENV !== 'production') {
initProxy(vm)
} else {
vm._renderProxy = vm
}
// expose real self
vm._self = vm
initLifecycle(vm)
initEvents(vm)
initRender(vm)
callHook(vm, 'beforeCreate')
initInjections(vm) // resolve injections before data/props
initState(vm)
initProvide(vm) // resolve provide after data/props
callHook(vm, 'created')
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
vm._name = formatComponentName(vm, false)
mark(endTag)
measure(`vue ${vm._name} init`, startTag, endTag)
}
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}
}